
Publication

Generating Animatable 3D Cartoon Faces from Single Portraits
Chuanyu Pan, Guowei Yang, Taijiang Mu, Yu-Kun Lai
Computer Graphics International (CGI) 2023, and Journal Virtual Reality & Intelligent Hardware (VRIH)
This work introduces a novel framework to generate animatable 3D cartoon faces from a single portrait image. We first transfer an input real-world portrait to a stylized cartoon image with a StyleGAN, then we propose a two-stage reconstruction method to recover the 3D cartoon face with detailed texture. Compared with prior arts, qualitative and quantitative results show that our method achieves better accuracy, aesthetics, and similarity criteria. Furthermore, we demonstrate the capability of real-time facial animation of our 3D model.
[ Paper ]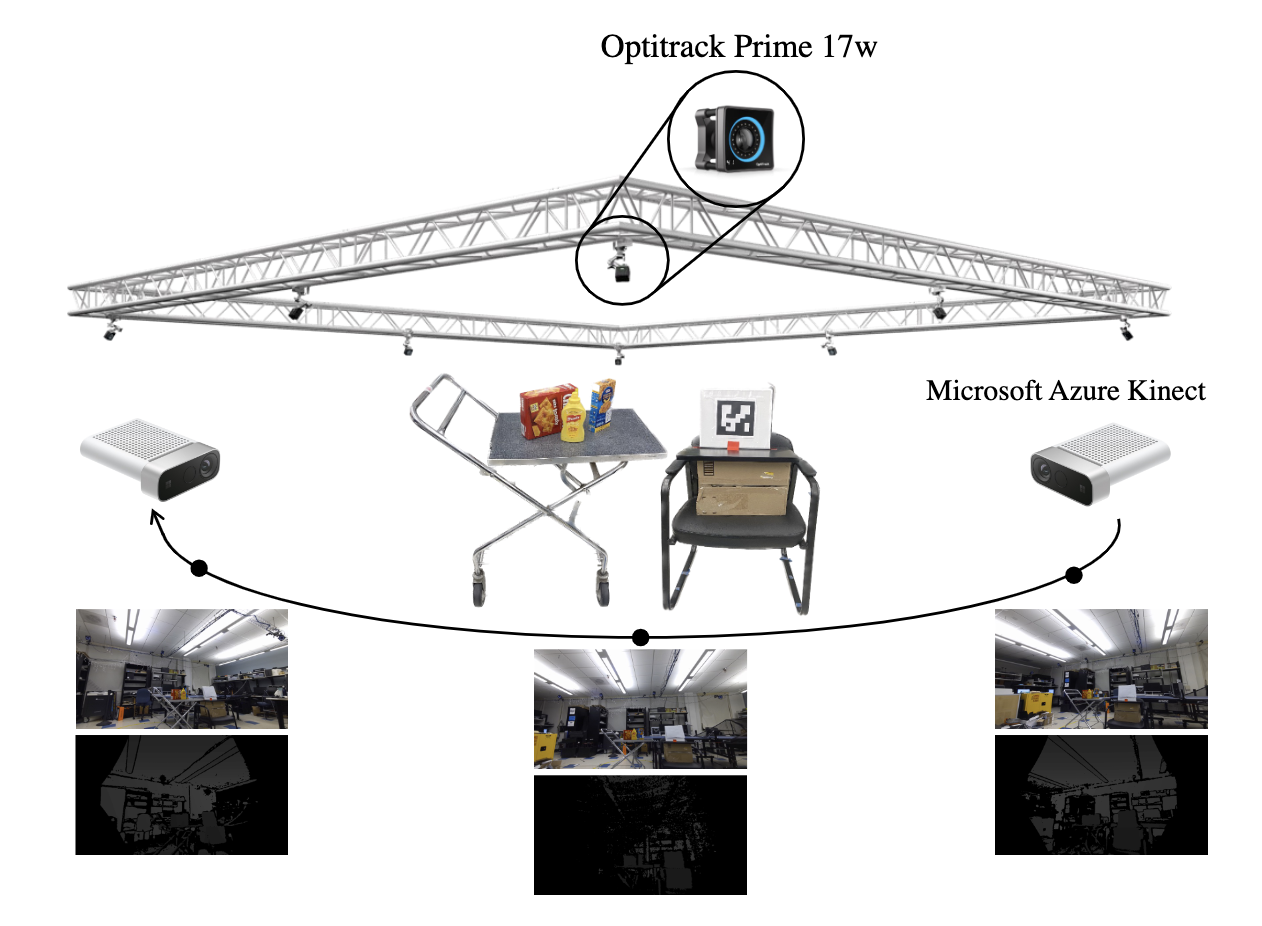
Digital Twin Tracking Dataset (DTTD): A New RGB+Depth 3D Dataset for Longer-Range Object Tracking Applications
Weiyu Feng*, Seth Z. Zhao*, Chuanyu Pan*, Adam Chang, Yichen Chen, Zekun Wang, Allen Y. Yang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, the 2nd Workshop Challenge on Vision Datasets Understanding
In this work, we create a novel RGB-D dataset, called Digital-Twin Tracking Dataset (DTTD), to enable further research of the 3D object tracking problem and extend potential solutions towards longer ranges and mm localization accuracy. To reduce point cloud noise from the input source, we select the latest Microsoft Azure Kinect as the state-of-the-art time-of-flight (ToF) camera. In total, 103 scenes of 10 common off-the-shelf objects with rich textures are recorded, with each frame annotated with a per-pixel semantic segmentation and ground-truth object poses provided by a commercial motion capturing system. Through experiments, we demonstrate that DTTD can help researchers develop future object tracking methods and analyze new challenges.
[ Project Page ][ Paper ]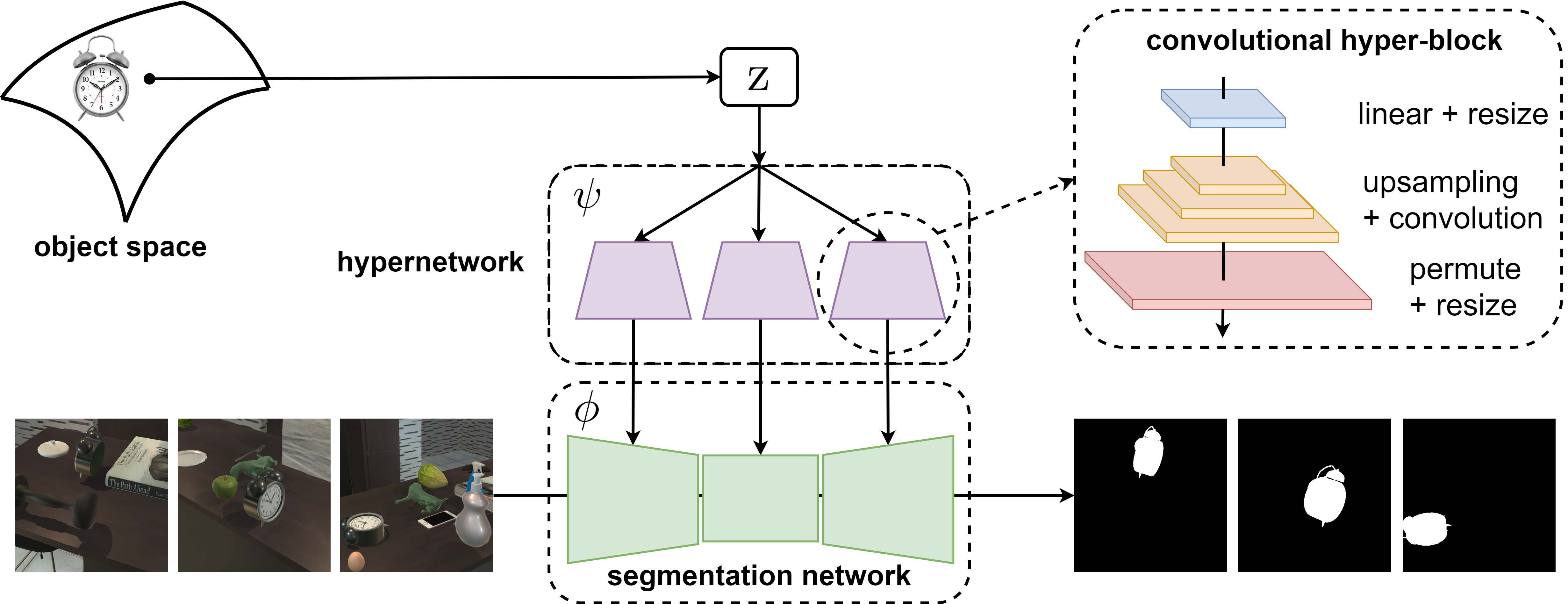
Object Pursuit: Building a Space of Objects via Discriminative Weight Generation
Chuanyu Pan*, Yanchao Yang*, Kaichun Mo, Yueqi Duan, Leonidas J. Guibas
The International Conference on Learning Representations (ICLR), 2022
We propose a framework to continuously learn object-centric representations for visual learning and understanding. Our method leverages interactions to effectively sample diverse variations of an object and the corresponding training signals while learning the object-centric representations. Throughout learning, objects are streamed one by one in random order with unknown identities, and are associated with latent codes that can synthesize discriminative weights for each object through a convolutional hypernetwork.
[ Project Page ][ Paper ][ Video ]
Robust 3D Self-portraits in Seconds
Zhe Li, Tao Yu, Chuanyu Pan, Zerong Zheng, Yebin Liu
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 (Oral presentation)
We propose an efficient method for robust 3D self-portraits using a single RGBD camera. Benefiting from the proposed PIFusion and lightweight bundle adjustment algorithm, our method can generate detailed 3D self-portraits in seconds and shows the ability to handle extremely loose clothes. To achieve highly efficient and robust reconstruction, we contribute PIFusion, which combines learning-based 3D recovery with volumetric non-rigid fusion to generate accurate sparse partial scans of the performer.
[ Project Page ][ Paper ][ Video ]